The Night Shift
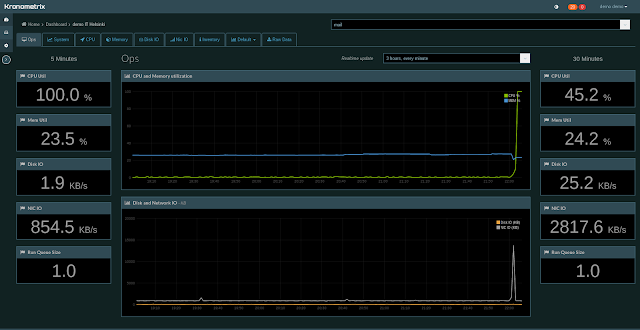
The TV Series ... Night Shift ? Nope, this is Kronometrix appliance for night workers, operators, sleepless system administrators and for the rest of us, working late. An appliance ? What do you mean ? To be serious about monitoring you better have an application running on a cloud platform, right ? Public or private, whatever that is, Google, Amazon, Azure or on a internal network powered by OpenStack, VMware ... preferable deployed over a large number of nodes, using large memory configurations and offering advanced dashboards to keep track of hundreds of metrics collected from machines, storage, network devices, applications all available and ready to be ... read and digested by anyone. The duty admin is confused, what dashboards will be needed for basic performance monitoring and SLA and what metrics these dashboards should include ? We took a simpler approach with Kronometrix, which can be deployed on a cloud computing platform if really needed, which was designed ...

